As a front-end developer you’ve probably been hearing about WebAssembly for a long time. Below I will show you how in 5 simple steps you can start using the code written in C, calling it directly from the Angular component. I won’t write down what WebAssembly is but I will show you how to use it right away:
1. Download the Emscripten library from Github and install it
2. In the app.tsconfig.json change the module from es2015 to esnext.
3. Write your code in C
4. Compile it to .js and .wasm
5. And voila, you can already call the C code from Angular
The results are amazing. It’s two times faster than the vanilla JS Fibonacci method!
You probably don’t need WASM when you develop a simple login form, or another table on the page. But, once you have developed your own map implementation, or when you fall in love with CityBound, you will see that WASM is the right solution for you.
Check out some of our best app design ideas: simple, plain and effective
Machine Learning has been increasingly entering every area of our lives over recent years. From the recognition of photos and voices to, intelligent hints and suggestions online and even in our cars. According to a study by mckinsey.com, by 2030, 30% of the work that people currently do will be taken over by machines. In software companies it will be even more so. Worse-case scenario – you’re afraid that they’ll make you redundant from your favorite job, and they’ll replace you with machines. Don’t think that. The machine will rather take over the basic work leaving you to focus on more innovative things. And this is how AI can support our daily administrative tasks…Let’s take a closer look to the Jira task estimation based on the Azure Machine Learning predictive model.
AI powered planning with Jira
We spend 2 hours twice a month estimating the backlog tasks. For a team of 5 people that is 10 hours, and on a monthly basis 20 hours of planning. It’s quite a lot, given that the programmer, hopefully, earns on average 30 USD per hour. Annually it means 8 thousands USD spent on planning alone. In this case, 4 additional people from different departments take part in the planning as they are responsible for the whole process of delivering the software to the client.
On the one hand, without planning, the project would certainly not look as it should. And inevitably, the level of complexity and structure would decline over time. On the other…few programmers like the so-called “Meeting Day”. It’s the day when you think of all the things you could be doing, but can’t because you’re at a meeting.
Jira is a well-structured tool where many processes can be simplified, but maybe Jira could give something more just by itself. You have backlog of 200 tasks. You read the content of the task. After 5 seconds you know, more or less, how much time it will take you to complete each task (as long as the content is written legibly, concisely, and illustratively). Clear situation – the task is priced, you move on to the next task. This is another task in a row that you priced to 3 Story Points. You have already done 20 similar tasks.
Azure Machine Learning Planning – Configuration Model
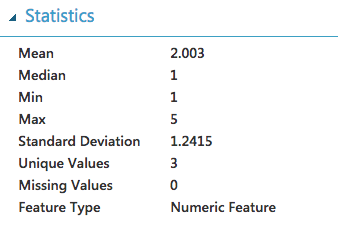
The first step to include Azure Machine Learning to our planning process is to export current tasks from Jira to CSV so that they can be analyzed. Unfortunately, Jira exports the CSV file in a way that is not compatible with what we expect. The file is very dirty (spaces, tabs, enters, html code). Azure ML cannot import it properly either. Additionally, the team valued the tasks according to the Fibonacci sequence on a scale of 0,1,2,3,5,8,13. For our calculations it is too big a gap – we will simplify it to the form of EASY(1), MEDIUM(3), DIFFICULT(5). We export the data to a html file and then parse it using NodeJS to a format that we can accept. https://gist.github.com/ssuperczynski/b08d87843674eb4be64cb0fe7f658456 After importing a new CSV file to Azure ML we get the following task distribution.
Since our JS script only helped us to pre-prepare the file, we now have to further prepare it for more analysis. Steps we have already taken:
merge title with description,
drop html tags (this step will be explained later),
Further steps that I have not done, but they can significantly influence the final result. In order to verify the truthfulness of the estimate it is necessary to attach it one by one and verify the final effect.
Do not cut out html tags (the project has tasks for frontenders, where html tags sometimes have a key meaning in the estimation of the task).
Some of the tasks have French words – it is questionable whether they are significant, here we should make changes at the level of project management in Jira.
Separation of frontend and backend tasks. Currently, despite the fact that each task has its own EPIC, we do not attach it, so the front and back tasks are combined into one backlog.
The number of tasks is too small – the more tasks the better model
The current Azure ML scheme is as follows After making all the necessary modifications, the sentence that initially looked like this: Create table to log user last logins. This omit issue with locks on user table Is changed to: creat tabl log user login omit issu lock user tabl Below is a graph of word statistics for tasks larger than 5SP.
The next step is to analyze the words from two angles. Unigram – a method that counts all single occurrences of words. In our case, the method may prove ineffective, because the content of “Change font under application form”. – having 1 SP and “add two new child forms under application form” has 5 SP points to the word “application form” which once has 1SP and another 5SP. Bigram, Trigram, N-gram – based on N word statistics, where N is 2, 3 and so on. I chose the N-gram method, which turned out to be much more effective. In N-gram analysis we stop comparing strings, and switch to on hash – this comparison works faster, and because our database will continue to grow with time, comparisons will be faster.
Once the N-grams analysis is created, we can create and train our model, taking 70% of the data as the data to train, and 30% as test data.
The last step is to give our scheme the ability to introduce content into the analysis, and to show the level of difficulty as simulated by the model.
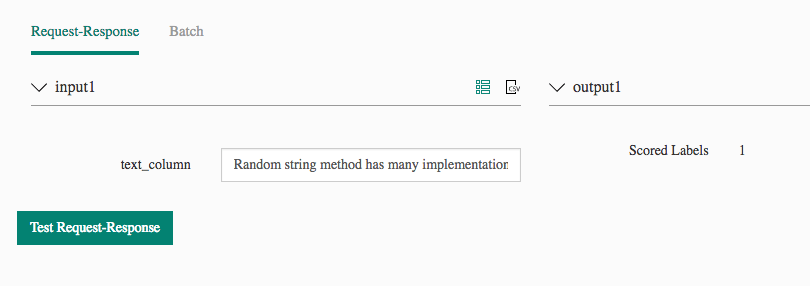
The tests used were those of my colleagues from the project, who themselves gave me the content of the tasks for analysis. Here are the results:
oAuth Refresh token doesn’t work – Azure ML – easy – friends – easy
Add BBcode feature to the form – Azure ML – easy – friends easy
Fix the styles for upload button – Azure ML – easy – friends – easy
Message form refactor– Azure ML – difficult – friends – difficult
Random string method has many implementations – unify them into one – Azure ML – easy – friends – easy
Summing up
As you can see in the above 5 examples, the accuracy of our program was 100%, despite the fact that there are places where we can improve our model. Based on our tests overall accuracy was around 80%.
At the moment it can be used during planning – for tests, but in the near future to efficiently inform the customer how much the task will cost and whether it should be divided into pieces – and all this before planning.
The next step is to build a Jira plugin and include it right next to the task description.
Confitura fascinates me every year. So many great talks, and this year was definitely the strongest one so far, especially in terms of Big Data technologies. I always thought it was the paid conferences that attracted the top speakers. I was wrong. Confitura has shown that a free entrance can guarantee the same level of quality as a paid one. In this case, I would say the level was even higher. Why? Just take a look at these presentations.
Sławomir Sobótka: C4 – a light approach to architecture documentation
I was pretty excited to attend to this talk, and I wasn’t disappointed. It seemed like he was describing me personally. He pointed out how many mistakes every developer makes. Thanks to this presentation, I realized how important it is to include a short description of why a given technology stack has been chosen into every project. For my current project, I’ve chosen Cassandra as a database, and Apache Spark as a tool to filter huge amounts of data. In CONTRIBUTION.md, I put a long description of why Cassandra has been chosen. Since it doesn’t have JOIN and GROUP BY it might be really hard to understand how it works properly. Thanks to CONTRIBUTION.md, each new developer now knows how to use it. Additionally, it’s good to show some use cases, your thoughts why you’ve chosen this particular technology stack and not another. It could prevent many mistakes or inaccuracies in the future. The presentation is available here [PL] https://youtu.be/T12Fdqf6ReQ?t=7h33m10s
Maciej Próchniak: Streams, flows and storms – How not to drown with your data
Such a nice guy to listen to. After his presentation, I realized how much better Kafka is compared to other message brokers. I can’t say much about Apache Flink and Kafka, because I’ve only used Spark Streaming before, but check out the video I attached below. The presentation is very professional, and I really wanted to mention it. Presentation available here [PL] https://youtu.be/RFstLZc_2y8?t=1h34m34s [EN] https://www.youtube.com/watch?v=-L_Rc6ElqJ0
Andrzej Ludwikowski: Cassandra – Lessons learned
This presentation confirms my opinion that we chose the right database for one of our projects. It’s based on time series, and it works in connection with Kafka and Apache Spark. As I wrote before, this database has no JOIN and GROUP BY and Andrzej confirmed my belief that the way we store data in this database and maintain data consistency is the right way indeed. Data duplication in Cassandra is ok, you don’t need to care about redundancy. Nowadays, SSD disks are relatively cheaper than RAM, so whether you have 100GB of data or 300GB – it costs you nothing. When you have 1GB of data, and no redundancy, you must do joins – it costs money. You add more RAM. RAM is much more expensive than SSD disks. This is the clue. The video is not available yet, but hope it will be uploaded soon. Such a good presentation.
Grzegorz Piwowarek: Javaslang – Functional Java the right way
Each Java programmer should definitely start using http://www.javaslang.io. As a Scala programmer, I was really surprised that Java finally has the same options as Scala has, available though this library. For example, Optionals with the Guards: Match(optional).of( Case(Optional($(v -> v != null)), "defined"), Case(Optional($(v -> v == null)), "empty") ); By using it with Try you can, for example, handle each error using if statement in a nice, functional way. A result = Try.of(this::bunchOfWork) .recover(x -> Match(x).of( Case(instanceOf(Exception_1.class), ...), Case(instanceOf(Exception_2.class), ...), Case(instanceOf(Exception_n.class), ...) )) .getOrElse(other); The video is not yet available either. Thanks to Grzegorz, I found a really cool library. This is the thing about every IT conference. Sometimes you need just a couple of minutes to find a new way to solve an issue. Other times, you find a new library, or you meet a great new speaker. And as Confitura has shown – you don’t need to pay for this knowledge. I’ll be on the lookout for Big Data technologies news (and you can read a bit more about Big Data from me here). I apologise for not mentioning anyone else, but it’s impossible to be on each session if there are 5 concurrent ones!
Many AngularJS developers don’t know how to properly use $watch() and $watchCollection(), and they write their own functions to track changes objects. Below is a piece of simple code to demonstrate differences between this two functions and situations when to use them.
$watch() is used to watch changes, for example in some input fields. This function always returns old value and new value.
$watchCollection() is used when trying to push something to a collection, or when removing some elements from it. This function returns previous collection and new collection.
And the third option. If you would like to detect changes inside your collections (deep watch), for example when you have collections and you want to modify some elements in ng-repeat you should again use $watch() function, but as a third parameter put boolean TRUE.
This is the first part of series of articles on building real-time, highly scalable applications using AngularJS and Node.js frameworks.
author:Sebastian Superczyński
Manage Cookie Consent
We use cookies to optimize our website and our service.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.
We use technologies like cookies to store and/or access device information. We do this to improve browsing experience and to show personalized ads. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.