

Remember static HTML web pages — sometimes with parts of PHP code wrapped by PHP tags? One of the oldest web pages on the web I know is the fantastic gem of internet history — the Space Jam webpage.

Source: https://www.warnerbros.com/archive/spacejam/movie/jam.htm
Created in 1996, it certainly was a very fancy and modern website at the time. That mind-blowing cosmic background and a stellar menu set trends for people surfing the web on a dial-up connection. Nowadays, websites look different, and the Space Jam site now may look like a high school HTML project.
Today, websites have to be more ornate rather than having a single dynamic presentation for visitors. They should be more unique for each and every client who visits the site. Also, the websites should be personalized and show individual information which visitors expect to see. User data and user behavior form the basis of website personalization. Naturally, the information about users is very important for any web app owners. By analyzing data, drawing conclusions, and applying targeted changes converts into more revenue.
Why do we need this data?
There are many uses for data. First thing that comes to mind is a personalized newsletter. Nowadays, only customised emails are rays of hope that the user will open it and click the links of interest. It’s not the only way to use this data. You can also personalize the offer and the special promotions for customers. These ideas spread to mind immediately, but anyone who cares about their business will come up with new ways to use the data. Take a look at reports concerning the issue, it’s helpful to to make a decision which direction to take your app. Make sure to see which the new functionalities would be a welcome change. However, most of the benefits from handling this data are usually claimed by UX/UI specialists. According to their analysis, the changes introduced to the user interface and to certain app processes to make it more user-friendly, which may be converted into real money.
Brace yourself, problems are coming!
Collecting such an amount of data may pose numerous problems for software architects. They have to take into account the factors which make the building process difficult because the application should be fast and scalable. Such problems will definitely occur, when it does ensure: high performance of the application, stability, openness for modification and collecting huge amount of data to be analyzed. It’s not easy to handle all these requirements. Experienced software architects have wide knowledge about design patterns and know many tools to help them accomplish the assigned tasks.
In addition, the situation is facilitated by the fact that not all of these problems should be dealt with immediately whereas some of them can be handled even after a few days. Those actions are, for example, analyzing data or sending mails. These steps are necessary in order to draw up a proper report, but still it doesn’t have to be done immediately. It’s enough to run these process once per week to prepare the weekly report or you can even skip that and only go for the monthly report. These things can be done asynchronously to avoid any delays in the app but to achieve this we need to define the processes which control them and other procedures which will be delegates to these actions.
In order to go about the issue reasonably it is necessary to gather some basic knowledge concerning CQRS and Event Sourcing. In this article, we will explain the CQRS approach in a simple way, and in the second part we will go deeper into the CQRS topic. Moreover, Event Sourcing will be explained and the reasons why these two concepts are interrelated will be provided.
Here comes CQRS
CQRS stands for Command Query Responsibility Segregation, as described by Greg Young, and it means that methods can be either categorised as a command or a query. To explain CQRS it’s worth to start off with CQS (Command Query Separation). CQS, presented by Bertrand Meyer, is said to divide object methods into 2 groups: those to be read and those to be written. In such a case the command method doesn’t provide information back and the query method shouldn’t have any side effect on the system. The main difference between CQS and CQRS is that CQS places commands and queries into different methods in the object, CQRS, however, puts commands and queries into different objects.
Commands – they change the state of the application but don’t provide information back.
Queries – they return the results but they don’t change the state of the application.
”Asking a question should not change the answer.”
To speak bluntly, if a question falls into another model, then a different answer will be given. These two models should be independent, that is why responsibility is divided into commands and queries. In other words we can say that the model is divided l into the command part and the query part. As a result we should use different models for updates and a different one for queries. On one hand such an approach brings us lots of small details into our application, but on the other it provides simplicity while developing an app at same time.
To illustrate the concept better, let’s compare the traditional approach and the CQRS
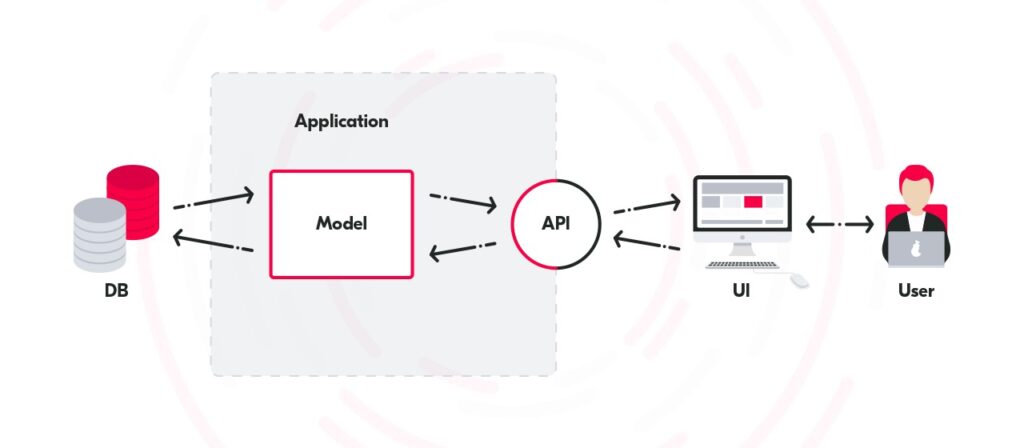
In this approach we use the same model for reading and updating a database, it works well for small apps and it tracks i user behavior. The User communicates with the app by any chosen API, it can be either a website or a phone app, next the app in this model handles any read or written action. But when a more complex solution for the bigger system is required then the CQRS pattern would be a better choice.
Here, a very simple implementation of CQRS has been presented. Now, there are two models instead of one; one of them seems perfect for reading data whereas the other one for writing data. Naturally, we can have more than only one model for queries and one for commands, it all depends on the application itself , but to explain this solution such a simple implementation is a good choice. Once again the user of the UI interacts with the app, next the app handles the request, but in this case, it uses two separate models for each written or read action.
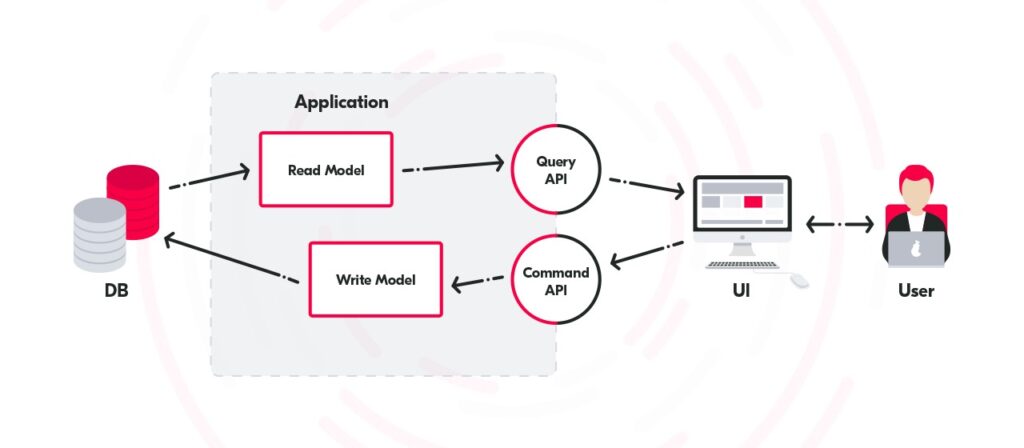
This is just a quick and simple introduction to the CQRS pattern. The next article will further focus on and develop the CQRS thread, it show more complex implementations and explain what Event Sourcing is. Furthermore, the next article will provide helpful information on collecting user data and discuss the reasons why CQRS and Event Sourcing can interrelate.


