Machine Learning has been increasingly entering every area of our lives over recent years. From the recognition of photos and voices to, intelligent hints and suggestions online and even in our cars. According to a study by mckinsey.com, by 2030, 30% of the work that people currently do will be taken over by machines. In software companies it will be even more so. Worse-case scenario – you’re afraid that they’ll make you redundant from your favorite job, and they’ll replace you with machines. Don’t think that. The machine will rather take over the basic work leaving you to focus on more innovative things. And this is how AI can support our daily administrative tasks…Let’s take a closer look to the Jira task estimation based on the Azure Machine Learning predictive model.
AI powered planning with Jira
We spend 2 hours twice a month estimating the backlog tasks. For a team of 5 people that is 10 hours, and on a monthly basis 20 hours of planning. It’s quite a lot, given that the programmer, hopefully, earns on average 30 USD per hour. Annually it means 8 thousands USD spent on planning alone. In this case, 4 additional people from different departments take part in the planning as they are responsible for the whole process of delivering the software to the client.
On the one hand, without planning, the project would certainly not look as it should. And inevitably, the level of complexity and structure would decline over time. On the other…few programmers like the so-called “Meeting Day”. It’s the day when you think of all the things you could be doing, but can’t because you’re at a meeting.
Jira is a well-structured tool where many processes can be simplified, but maybe Jira could give something more just by itself. You have backlog of 200 tasks. You read the content of the task. After 5 seconds you know, more or less, how much time it will take you to complete each task (as long as the content is written legibly, concisely, and illustratively). Clear situation – the task is priced, you move on to the next task. This is another task in a row that you priced to 3 Story Points. You have already done 20 similar tasks.
Azure Machine Learning Planning – Configuration Model
The first step to include Azure Machine Learning to our planning process is to export current tasks from Jira to CSV so that they can be analyzed. Unfortunately, Jira exports the CSV file in a way that is not compatible with what we expect. The file is very dirty (spaces, tabs, enters, html code). Azure ML cannot import it properly either. Additionally, the team valued the tasks according to the Fibonacci sequence on a scale of 0,1,2,3,5,8,13. For our calculations it is too big a gap – we will simplify it to the form of EASY(1), MEDIUM(3), DIFFICULT(5).
We export the data to a html file and then parse it using NodeJS to a format that we can accept.
https://gist.github.com/ssuperczynski/b08d87843674eb4be64cb0fe7f658456
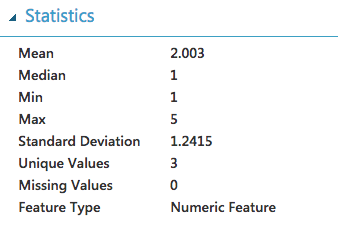
After importing a new CSV file to Azure ML we get the following task distribution.

Since our JS script only helped us to pre-prepare the file, we now have to further prepare it for more analysis.
Steps we have already taken:
- merge title with description,
- drop html tags (this step will be explained later),
- replace numbers,
- remove special chars.
Steps we need to take now:
- remove duplicate chars,
- convert to lower case,
- stem the words: driver, drive, drove, driven, drives, driving becoming drive,
- remove stopwords (that, did, and, should …).
Verification process
Further steps that I have not done, but they can significantly influence the final result. In order to verify the truthfulness of the estimate it is necessary to attach it one by one and verify the final effect.
- Do not cut out html tags (the project has tasks for frontenders, where html tags sometimes have a key meaning in the estimation of the task).
- Some of the tasks have French words – it is questionable whether they are significant, here we should make changes at the level of project management in Jira.
- Separation of frontend and backend tasks. Currently, despite the fact that each task has its own EPIC, we do not attach it, so the front and back tasks are combined into one backlog.
- The number of tasks is too small – the more tasks the better model
The current Azure ML scheme is as follows
After making all the necessary modifications, the sentence that initially looked like this:
Create table to log user last logins. This omit issue with locks on user table
Is changed to:
creat tabl log user login omit issu lock user tabl
Below is a graph of word statistics for tasks larger than 5SP.

The next step is to analyze the words from two angles.
Unigram – a method that counts all single occurrences of words. In our case, the method may prove ineffective, because the content of “Change font under application form”. – having 1 SP and “add two new child forms under application form” has 5 SP points to the word “application form” which once has 1SP and another 5SP.
Bigram, Trigram, N-gram – based on N word statistics, where N is 2, 3 and so on.
I chose the N-gram method, which turned out to be much more effective.
In N-gram analysis we stop comparing strings, and switch to on hash – this comparison works faster, and because our database will continue to grow with time, comparisons will be faster.


Once the N-grams analysis is created, we can create and train our model, taking 70% of the data as the data to train, and 30% as test data.

The last step is to give our scheme the ability to introduce content into the analysis, and to show the level of difficulty as simulated by the model.

The tests used were those of my colleagues from the project, who themselves gave me the content of the tasks for analysis.
Here are the results:
- oAuth Refresh token doesn’t work – Azure ML – easy – friends – easy
- Add BBcode feature to the form – Azure ML – easy – friends easy
- Fix the styles for upload button – Azure ML – easy – friends – easy
- Message form refactor – Azure ML – difficult – friends – difficult
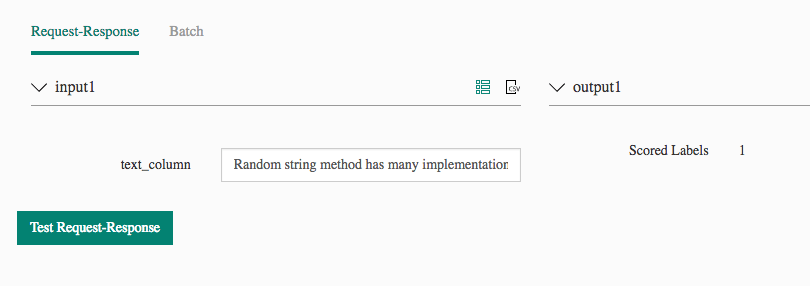
- Random string method has many implementations – unify them into one – Azure ML – easy – friends – easy

Summing up
As you can see in the above 5 examples, the accuracy of our program was 100%, despite the fact that there are places where we can improve our model. Based on our tests overall accuracy was around 80%.
At the moment it can be used during planning – for tests, but in the near future to efficiently inform the customer how much the task will cost and whether it should be divided into pieces – and all this before planning.
The next step is to build a Jira plugin and include it right next to the task description.