Have you ever used Spark ML? How difficult was it (or it is)? If you’re familiar with Scala or Java, it might take a while to get the hang of using this library properly. But what if you don’t code in Scala or Java, but – let’s say – PHP or Javascript? What if you’re not that great at programming yet? Whichever case you fall into, you should definitely take a look at Azure ML.
Why it is easier to use it than Spark Machine Learning?
Because you don’t even have to know any programming languages.
How does Azure Machine Learning work?
Azure ML creators emphasize readability and ease, so they created a machine learning library based on Lego blocks. Every module has different blocks (like functions in any programming language). Every block has some input (like the parameters method) and some output (like “return”).
In the example below, I’ll try to show you how to build a simple prediction. I’ll demonstrate how to calculate the amount of money a given shop can earn based on some parameters.
Let’s place the first block.

As you can see here, this block reads data from some source (JSON, CSV, XML, plain text). There is a dot below to connect it with another block. Our “Reader” returns those data, and our “Split data” block takes those data as parameters.
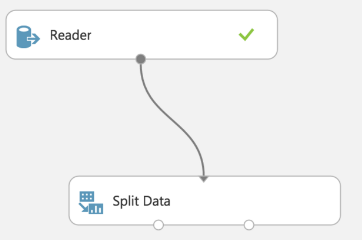
In this case, I’m connecting the reader with the splitter to prepare my model to use the Decision Tree. The “split data” block now splits my data into two parts, trained data and test data.
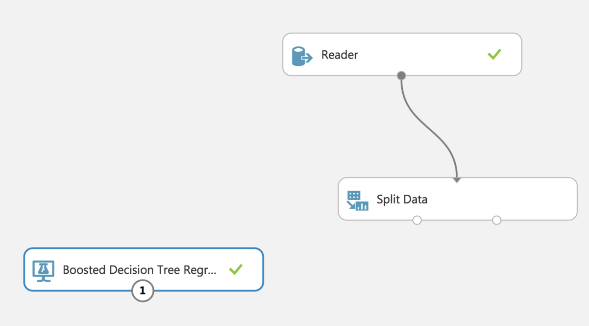
Because Azure ML (naturally) has blocks for predictions, I’m using another one called ”Boosted Decision Tree Regression”. Following Microsoft specifications, the “Boosted Decision Tree” is:
A machine learning technique for regression problems. It builds each regression tree in a step-wise fashion, using a predefined loss function to measure the error in each step and correct for it in the next. Thus the prediction model is actually an ensemble of weaker prediction models.
In regression problems, boosting builds a series of trees in a step-wise fashion, and then selects the optimal tree using an arbitrary differentiable loss function.
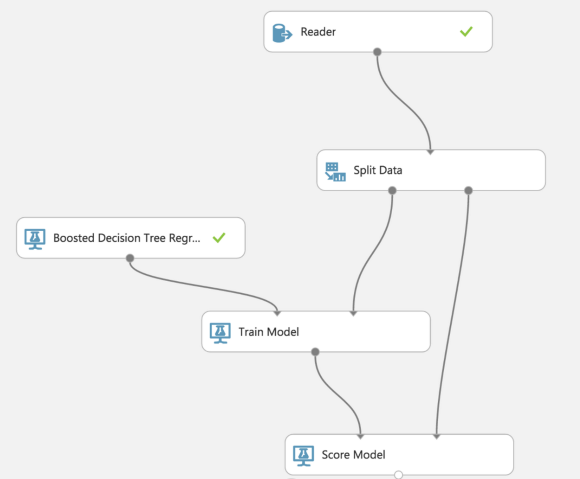
To train my model, I’m connecting split data with the Decision Tree to make the first prediction.
When we hit the “play” button, the model starts training our data. After it’s done we must add the last brick to see the results.
Following Microsoft – the Train model is a classification or regression model, and a kind of supervised machine learning. Therefore, you must provide a dataset that contains historical data from which patterns can be learnt. The machine learning model uses the data to extract statistical patterns and build a model. The Score model can be used to generate predictions using a trained classification or regression model. The predicted value can be in many different formats, depending on the model and your input data:
- If you are using a classification model to create the scores, the output is a predicted value for the class, as well as the probability of the predicted value.
- For regression models, it generates just the predicted numeric value.
- For image classification models, the score might be the class of object in the image, or a Boolean indicating whether a particular feature was found.
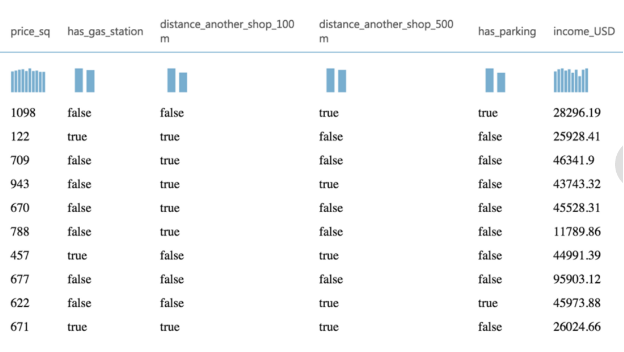
I used simple data available on the Internet to calculate how much money a given shop can earn. It was based on several factors: where the shop was built, whether it’s far from another shop, whether the shop has parking or a bus stop, etc. More parameters equal more accurate results. This is my data with real prices (income_USD):
This is my prediction:
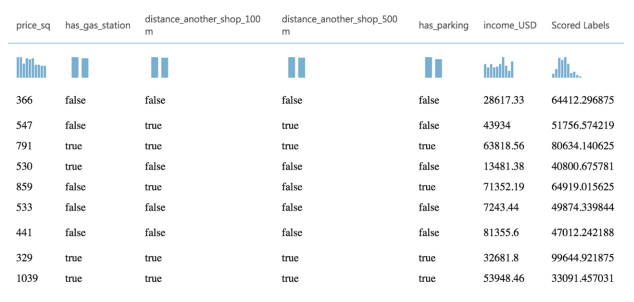
Please note that the predicted price might be totally different, I just included a few parameters. This prediction might need a couple hundred or thousands of parameters to be really accurate. Well, were it that easy, any analyst would use it to know exactly how much a given shop will earn.
This is just one of many posts to come about Machine Learning and the ease with which Azure introduces to ML. Didn’t you notice something weird, though? Yep, we didn’t use even one line of code to build our prediction. Of course, you can later use some bricks called “R script” or “Python script” to implement your own standards, libraries etc.. but it’s OK not to use them.
Feel free to comment, or ping me on Twitter at @ssuperczynski if you have any questions related to Azure ML.